AI에 기업 문화가 있다면 어떨까요?
“세상에는 사람보다 AI 에이전트가 더 많아질 것입니다.” — Mark Zuckerberg
멀티 에이전트들이 점점 더 주도권을 잡고 있습니다. 연구에 따르면 30개 이상의 에이전트를 사용하는 AI 시스템이 단순한 LLM 호출보다 거의 모든 작업에서 더 뛰어난 성능을 발휘하며, 환각을 줄이고 정확성을 향상시킵니다.
그렇다면 에이전트들은 서로 어떻게 협력해야 할까요? 소프트웨어 엔지니어링 작업에서 AI 성능을 향상시키기 위한 방법을 탐구하던 중, 한 가지 아이디어가 떠올랐습니다: AI 에이전트 간의 상호작용을 대형 기술 기업의 조직도처럼 구조화하면 어떨까요?
다음은 Apple, Microsoft, Google, Amazon 등과 같은 기업의 조직 구조를 모방하여 AI 에이전트를 그룹으로 조직한 후 얻은 주요 시사점입니다:
- Microsoft와 Apple처럼 여러 “경쟁” 팀이 있는 회사는 중앙 집중식 계층 구조보다 뛰어난 성과를 보였습니다.
- Google, Amazon, Oracle과 같이 중요한 결정을 내리는 한 명의 리더가 있는 단일 실패 지점이 있는 시스템은 성과가 저조했습니다.
- 대형 기술 회사의 조직 구조는 문제 해결 능력에 적지만 눈에 띄는 영향을 미쳤습니다.
소프트웨어 및 대형 기술 조직 이론
이전에는 AI 소프트웨어 엔지니어링 능력을 향상시키기 위해 SWE-bench(인기 있는 AI 소프트웨어 엔지니어링 벤치마킹 도구)에 더 많은 에이전트를 추가하는 방법이 시도되었습니다. 그러나 단순히 에이전트 수를 늘리는 것만으로는 해결률이 극적으로 개선되지는 않았습니다 (참고: SIMA 에이전트). 그렇다면 AI 에이전트를 소프트웨어 엔지니어링에서 더 잘 작동하게 만들기 위해 어떻게 해야 할까요?
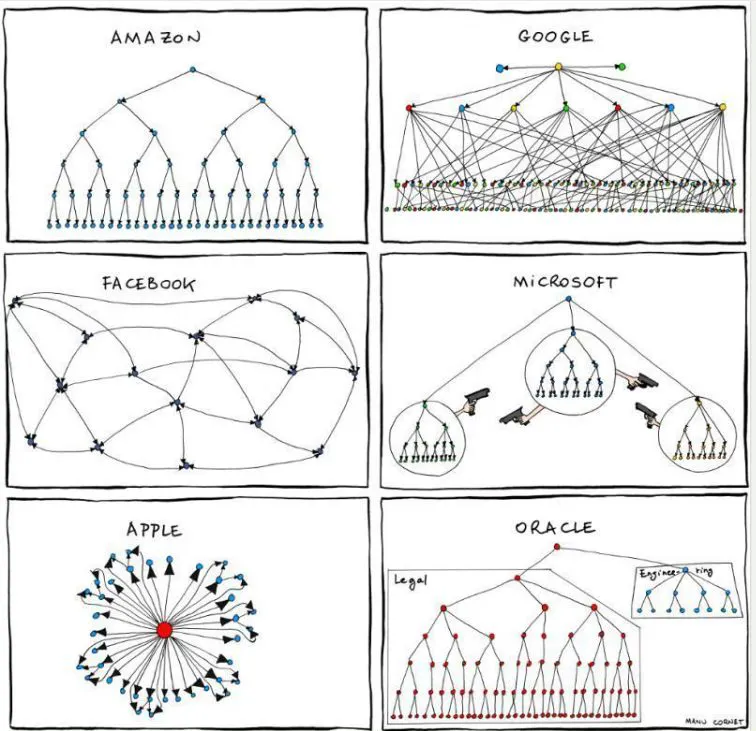
3주 전, James Huckle이 작성한 Conway's Law에 관한 게시물을 우연히 발견했습니다: "소프트웨어 및 제품 아키텍처는 그것을 만든 조직 구조의 반영일 수밖에 없다." 그는 Amazon, Google, Facebook, Microsoft, Apple, Oracle의 조직 구조를 극적으로 묘사한 일러스트를 통해, 대형 기술 기업에서 일하는 인간들처럼 멀티 에이전트 통신 구조도 문제 해결 접근 방식을 형성할 수 있다는 아이디어를 제안했습니다. James의 가설을 SWE-bench 사례에 테스트해 보려는 영감을 받았습니다.
실험 설정
저는 AI 에이전트를 서로 다른 기업에 있는 것처럼 조직하여, 6가지 조직 구조를 13개의 SWE-bench-lite "미니" 인스턴스에서 평가했습니다 (평가 속도를 높이고 재정적인 이유로 😃). 6개의 조직을 구성할 때 몇 가지 핵심 관찰을 바탕으로 멀티 에이전트 조직 설계를 진행했습니다:
- Amazon: 최상위에 하나의 “매니저”가 있는 이진 트리 구조. 이를 재현하기 위해 많은 에이전트가 코드 저장소 검색을 수행하고, 최종적으로 하나의 에이전트가 저장소 업데이트를 수행하도록 했습니다.
- Google: Amazon과 유사한 트리 구조이지만 중간 계층 간의 연결이 훨씬 많습니다. 이를 재현하기 위해 하나의 계층 내 모든 에이전트 결과를 집계하고, 그 결과를 다음 계층의 에이전트에 전달했습니다.
- Facebook: 계층 구조가 없지만 에이전트 간 연결이 많은 웹과 같은 조직. 원래의 에이전트 설계를 수정하여 다양한 에이전트 간 전환 가능성을 추가했습니다.
- Microsoft: 각기 다른 계층을 가진 경쟁 팀들. Amazon의 구조를 재활용하여 에이전트 수를 줄이고, 벡터 유사성 투표 방법을 사용해 세 번의 개별 실행 중 “최고의” 솔루션을 선택했습니다 (각 실행에는 계층 구조에 대한 약간의 조정이 있었습니다).
- Apple: 각기 다른 최소 구조를 가진 소규모 경쟁 팀들이 많다고 해석했습니다. Microsoft와 동일한 “최고의 솔루션” 방법을 사용했지만, 계층 구조 없이 많은 실행을 수행하고 각 실행에 대해 다른 전환을 사용했습니다.
- Oracle: 두 개의 다른 팀이 있었으며, 더 큰 “법률” 이진 트리와 더 작은 엔지니어링 트리가 있었습니다. 법률 팀은 코드 저장소를 검색하고 중요한 컨텍스트를 가져오는 에이전트로, 엔지니어링 팀은 실제로 코드를 작성하는 에이전트로 구성했습니다. 두 팀 모두 Amazon과 유사한 구조를 가지고 있으며, 상위 에이전트 하나가 정보 전달을 조정했습니다.
결과 및 SWE-bench-docker
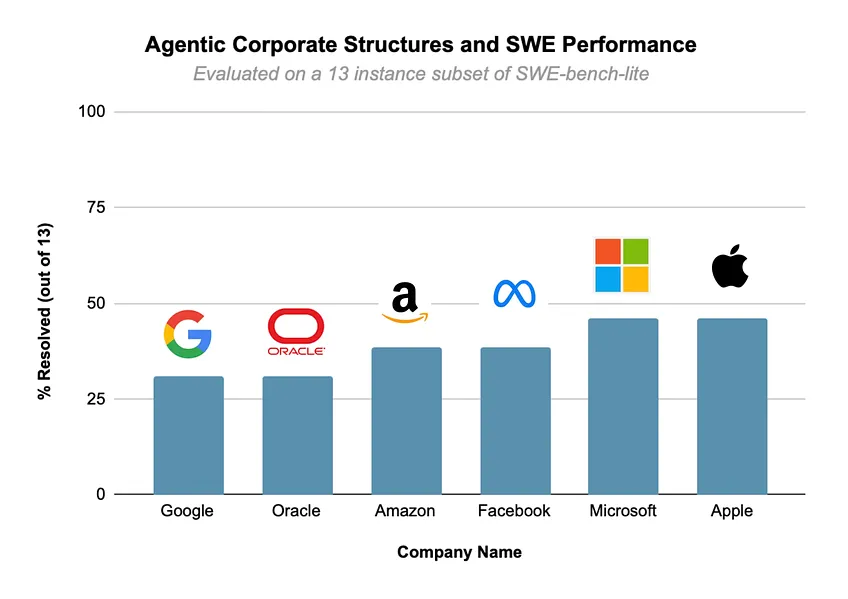
SWE-bench에서 각 패치를 평가하기 위해, SWE-bench 팀이 제공한 도커화된 SWE-bench 평가를 사용했습니다. 다음은 제 결과입니다:
조직도 성능 분석
다음은 다양한 기업 구조가 성과에 미친 영향을 관찰한 내용입니다:
- 경쟁 팀이 성공 가능성을 높입니다. 상위 두 성과자(Microsoft와 Apple)는 모두 문제를 해결하기 위해 경쟁하는 여러 팀이 있었던 반면, 다른 기업들은 하나의 거대한 팀이 단일 패치를 생성했습니다. 여러 팀은 문제 해결 접근 방식의 다양성을 증가시켜 문제를 해결할 확률을 높였습니다.
- 단일 실패 지점이 있는 구조는 성과가 좋지 않았습니다. 단일 실패 지점이란, 높은 수준의 관리자/에이전트가 실행 결과를 완전히 바꿀 수 있는 회사를 의미합니다 (예: Google, Amazon, Oracle). 여러 에이전트 간의 상호작용을 조정할 때, 한 에이전트가 실패하면 팀의 문제 해결 전략의 경로를 변경할 수 있는 잠재적인 문제가 발생할 수 있습니다. 단일 실패 지점이 있는 회사는 이러한 종류의 문제에 취약합니다.
또한, 상위 두 성과자인 Microsoft와 Apple은 세계에서 시가총액이 가장 큰 두 기술 기업입니다. 현실 세계에서 잘 작동하는 조직 구조가 AI 에이전트에게도 효과적임이 드러났습니다.
앞으로의 전망: SWE-bench 발전에 대한 생각
결과를 보면, 이 미니 벤치마크에서 다양한 기업 구조가 미친 영향은 예상된 대로였습니다 (1~2 인스턴스의 차이). 일반적으로, 에이전트를 더 많이 투입하거나 이 에이전트를 조직하는 방식을 변경하는 것(계층적이거나 에이전트 간 더 많은 연결을 가지는 방식)은 소프트웨어 엔지니어링처럼 복잡한 작업에서 성과를 조금씩 향상시킬 수 있습니다.
More Agents Is All You Need 연구에서는 정확도가 상당히 큰 폭으로 증가했음을 발견했습니다(~20%). 하지만 30개 이상의 에이전트를 사용한 후 성능은 눈에 띄게 평탄화되었고, 연구에 따르면 복잡성이 과도한 작업(SWE-bench와 같은 작업)에서는 모델의 추론 능력을 초과하여 성능 개선이 점점 줄어들 수 있습니다. 저는 SIMA에서도 이 발견을 확인했으며, 기본 아키텍처에서 최대 2-3%의 성능 향상을 달성했습니다(40개 이상의 에이전트와 함께). 이러한 소규모 성과 향상은 다른 비멀티 에이전트 아키텍처에서도 일관되게 나타날 것으로 예상합니다.
제 생각에는 벤치마크에서 더 큰 도약을 이루려면 에이전트의 실제 논리적 추론 능력, 또는 소프트웨어 문제를 실제로 해결하기 위해 사용할 수 있는 전략과 방법(또는 제공되는 방법)을 변경해야 합니다. 이것은 더 강력한 기본 모델(GPT-5?) 또는 에이전트에게 더 많은 도구(디버거, 린터, 자동화된 테스트)를 제공하는 형태로 이루어질 수 있습니다. 회사에서도 마찬가지입니다. 결국 더 똑똑한 직원을 고용하지 않거나 더 나은 자원을 제공하지 않으면, 그들의 산출물이 개선되지 않을 것입니다. 아무리 조직을 잘 구성하거나 사람 수를 늘려도 마찬가지입니다.
그러나 13개의 인스턴스에서의 성능은 전체 벤치마크에서의 실제 성능과는 상당히 다를 수 있으며, 단지 이 미니 서브셋에서의 차이도 Google과 Apple 간의 약 50% 증가와 같이 상당히 크므로 주목할 가치가 있습니다. 기본 모델이나 도구는 에이전트 소프트웨어 엔지니어링의 제한 요소일 수 있지만, 에이전트 통신 구조(기업 조직이든 아니든)를 실험하는 것은 기본 모델이 개선됨에 따라 반드시 테스트해야 하는 문제입니다. James Huckle의 말처럼, 이 개념은 AI 에이전트 설계에서 '중요한 하이퍼 파라미터'가 될 수 있으며, 각기 다른 조직 구조가 업무에 더 적합할 수 있습니다.
Comments ()